
-
info@forensicss.com
Send Email
-
11400 West Olympic Blvd, Los Angeles, CA 90064
310-270-0598
Confidentiality Guaranteed
310-270-0598
Confidentiality Guaranteed
04
Feb
Feb
A case gaze in PDF forensics: The Epstein PDFs
Internet investigation
The latest open of a tranche of files by the US Division of Justice (DoJ) below the “Epstein Files Transparency Act (H.R.4405)” has once extra prompted many contributors to intently witness redacted and sanitized PDF documents. Our old articles on the Manafort papers and the Mueller memoir, moreover to a gaze by Adhatarao, S. and Lauradoux, C. (2021) “Exploitation and Sanitization of Hidden Info in PDF Files: Fabricate Security Agencies Sanitize Their PDF files?,” in Proceedings of the 2021 ACM Workshop on Info Hiding and Multimedia Security, illustrate the importance of sturdy sanitization and redaction workflows when handling comfortable documents prior to open.
This text examines a tiny random dedication of the Epstein PDF files from a purely digital forensic point of view, specializing within the PDF syntax and idioms they possess, any malformations or uncommon constructs, and diverse technical aspects.
PDFs are extra not easy to analyze than many varied codecs because they’re binary files that require truly expert recordsdata, trip, and tool. Please point to that we did not analyze the contents of the PDF documents. No longer each and each PDF used to be examined. Any mention of merchandise (or appearance in display-shots) would not imply any endorsement or purple meat up of any recordsdata, merchandise, or companies in anyway. We’re not lawyers; this text would not constitute apt recommendation
We provide this recordsdata, in section, as among the crucial Epstein PDFs launched by DoJ are starting up to appear on malware prognosis sites (similar to Hybrid-Diagnosis) with varied kinds of unsuitable prognosis and misinformation.
26 December 2025 replace
After we would carried out our prognosis the DoJ launched a new dataset, DataSet 8.zip. This new ZIP file is 9.95 GB compressed and accommodates over 11,000 files, including 10,593 new PDFs totaling 1.8 GB and 29,343 pages (the longest doc has 1,060 pages). DataSet 8 also accommodates many well-known MP4 movies, Excel spreadsheets, and varied diverse files. The first PDF within the situation of 10,593 PDFs is VOL00008IMAGES�001EFTA00009676.pdf, and the final file is VOL00008IMAGES�011EFTA00039023.pdf. A cursory prognosis reveals pdfinfo properties the same to these from the earlier datasets, but we have not otherwise analyzed this new dataset.
Since our fashioned submit, varied social media and news platforms consider also been announcing “recoverable redactions” from the “Epstein Files”. We stand by our prognosis; DoJ has accurately redacted the EFTA PDFs in Datasets 01-07, and they originate not possess recoverable textual remark as alleged. As our article states, we did not analyze any diverse DoJ or Epstein-connected documents.
Let’s speak, the featured image in this Guardian news article (which used to be also picked up by the New York Instances) corresponds to VOL00004IMAGES�001EFTA00005855.pdf, as would possibly simply additionally be with out downside decided by looking out for the Bates Numbers within the EFTA “.OPT” recordsdata files. The recordsdata in this EFTA PDF is fully and accurately redacted; there’s no hidden recordsdata. The handiest extractable textual remark is about a garbled textual remark from the sorrowful-quality OCR and, as expected, the Bates Numbers on each and each page.
Within the few experiences we investigated (including from Forbes and Ed Krassenstein on each and each X (formerly Twitter) and Instagram), these tales misrepresent diverse DoJ files that were not section of the principle DataSets 01-07 open on December 19 below the EFTA. All PDFs launched below EFTA consider a Bates Number on each and each page starting up “EFTA”. These consist of “Case 1:22-cv-10904-JSR Yarn 1-1, Expose 1 to Govt’s Grievance towards JPMorgan Trek Monetary institution, N.A.” (ogle page 41) and “Case No: ST-20-CV-14 Govt Expose 1” (ogle page 19). These PDFs, beforehand launched by the DoJ, originate possess unsuitable and ineffective redactions, with murky boxes that simply imprecise textual remark, making “copy & paste” easy to come by better the textual remark that is otherwise hidden. Clearly, DoJ processes and programs within the past consider inadequately redacted recordsdata!
The files we examined
The tranche launched by DoJ on Friday, December 19 is on hand as seven “recordsdata models”, most with out downside downloaded as seven ZIP archives totaling magnificent below 2.97 GB. Each and each ZIP file accommodates a the same folder construction, with DataSet 6 being the irregular one out with a further high-stage folder. As soon as unzipped, the entire measurement is 2.ninety 9 GB. The tranche accommodates 4,085 PDF files, a single AVI (movie) file (positioned within the folder VOL00002NATIVES�001), and a pair of recordsdata files (.DAT and .OPT) for each and each ZIP archive. The “.OPT” files seem like CSV (Comma-Separated Values) but lack a heading row, whereas the “.DAT” files possess recordsdata regarding the Bates numbering. The prognosis we present right here is proscribed to the PDF files.
The PDF files are named and ordered sequentially everywhere in the folder construction, starting up with “EFTA00000001.pdf” in VOL00001 and ending with “EFTA00009664.pdf” in VOL00007, indicating that not decrease than 5,879 PDF files stay unreleased.
A random sampling of the PDFs for visual evaluation suggests that they are a combination of single and multi-page fat-page photos and scanned remark. OCR (Optical Character Recognition) used to be inclined to produce some searchable and extractable textual remark in not decrease than some files. “Shaded field” vogue redactions (with out textual remark reasons) are apparent. When carried out accurately, right here’s the suitable potential to redact, a long way extra primary than pixelating textual remark. The PDFs we sampled did not consist of any clearly “born digital” documents. Varied news sites are reporting very heavily redacted documents within this tranche.
File validity
A precursor to most forensic examinations is to set up whether or not the PDF files are technically legitimate (that is, conform to the principles of the PDF structure), since examining malformed files can with out downside lead to unsuitable results or irascible conclusions. Combining tools that employ diverse techniques gives the broadest imaginable recordsdata whereas making sure that tooling barriers are fully understood. Nonetheless, if the classic file construction or contaminated-reference recordsdata is wrong, varied tool would possibly well then plan diverse conclusions and/or form diverse Yarn Object Devices (DOMs).
Moreover to classic file construction, incremental updates (if any), and contaminated-reference recordsdata, PDF validity assessments consist of the objects that comprise the PDF’sDOM moreover to the file construction, incremental updates, and contaminated-reference recordsdata. To assess relationships between objects within the PDF DOM, some forensic prognosis tools leverage our Arlington PDF Info Mannequin, whereas others employ their very consider interior techniques.
Our prognosis of file validity, the utilization of a large number of PDF forensic tools, known handiest one minor defect (invalidity); 109 PDFs had a definite FontDescriptor Descent value moderately than a negative one. That is a moderately current (but minor) error, in overall connected with font substitution and font matching, that would not have an effect on the validity of the files total. One grunt forensic instrument reported a PDF version downside with some files, connected to the doc catalog Version entry, which kept a long way off from the instrument from extra verifying these grunt PDFs.
PDF variations
I’ve beforehand written regarding the unreliability of PDF version numbers. Peaceable, for forensic applications, they would possibly simply present insight into the DoJ’s tool, and whether or not improved tool would possibly consider performed better.
I inclined two diverse but many times inclined PDF grunt-line pdfinfo utilities on diverse platforms (Dwelling windows and Ubuntu Linux) to summarize details about these PDF files. When hasten towards the fat tranche of PDFs, I obtained two very diverse models of solutions! Without prolong, my spidey senses began to tingle, and I used to be once extra reminded of a key lesson in digital doc forensics – you are going to consider to not at all believe a single instrument!
| Reported PDF Version | Depend System A | Depend System B |
| 1.3 | 209 | 3,817 |
| 1.4 | 1 | 1 |
| 1.5 | 3,875 | 267 |
| TOTAL (can consider to be 4,085) | 4,085 | 4,085 |
The PDF version within the file header, “%PDF-x.y”, is nominally the first line in each and each PDF file (per the not-unreasonable assumption that the PDF files haven’t any “junk bytes” sooner than this PDF file identifier). Utilizing the Linux grunt line, you would possibly possibly possibly hasten in Linux “head -n 1 file.pdf” to extract the first header line from each and each PDF and compare it with the reported results from each and each instrument. Or hasten in Linux “grep -P --textual remark --byte-offset "%PDF-d.d" *.pdf” to substantiate that there don’t appear to be any junk bytes prior to the PDF header line.
The trigger of the adaptation reported within the table above is that System B isn’t accounting for the Version entry within the doc catalog of PDFs with incremental updates. We’ll next investigate whether or not right here’s attributable to malformed files or a programming error. When effectively accounting for incremental updates, on the other hand, System A is exclusively appropriate.
Utilizing the the same pdfinfo output (and again evaluating results from each and each tools), we are able to also immediate set up the next details:
- No PDF is tagged
- No PDF is encrypted
- No PDF is “optimized” (technically, Linearized PDF)
- No PDF has any annotations
- No PDF has any outlines (bookmarks)
- No PDF accommodates any embedded files
- None of the PDFs are varieties
- None of the PDFs accommodates JavaScript
Web page counts vary from 1 (in 3,818 PDFs) to 119 pages (in two PDFs), totaling 9,659 pages all over all 4,085 PDFs.
Incremental updates
PDF’s incremental updates characteristic permits a pair of revisions of a doc to be saved in a PDF file. Because the title implies, each and each location of deltas is appended to the brand new doc, forming a series of edits. When learn by conforming PDF tool, a PDF is constantly processed from the terminate of the file, effectively making employ of the deltas to the brand new doc and to any old incremental updates. Both the brand new doc and each and each incremental replace would possibly simply additionally be known by their respective “xref” and “%%EOF” markers (assuming that the PDF files are structured accurately).
For this investigation, we started by examining the very first PDF within the tranche: VOL00001IMAGES�001EFTA00000001.pdf. This PDF had diverse PDF variations reported by diverse variations of pdfinfo. A straightforward trick to verify if a PDF accommodates incremental updates is to gaze these particular markers whereas treating the PDF as a textual remark file (which it isn’t!):
$ grep -P --textual remark -–byte-offset "(xref)|(%%EOF)" EFTA00000001.pdf
371340:xref
371758:startxref
371775:%%EOF
372977:startxref
372994:%%EOF
373961:startxref
373978:%%EOF
These results (sorted by byte offset) demonstrate that EFTA00000001.pdf accommodates two incremental updates after the brand new file. The dearth of an “xref” marker sooner than the final two “startxref” markers demonstrate that neither incremental updates uses aged contaminated-reference recordsdata, but would possibly simply employ contaminated-reference streams (if any objects are changed).
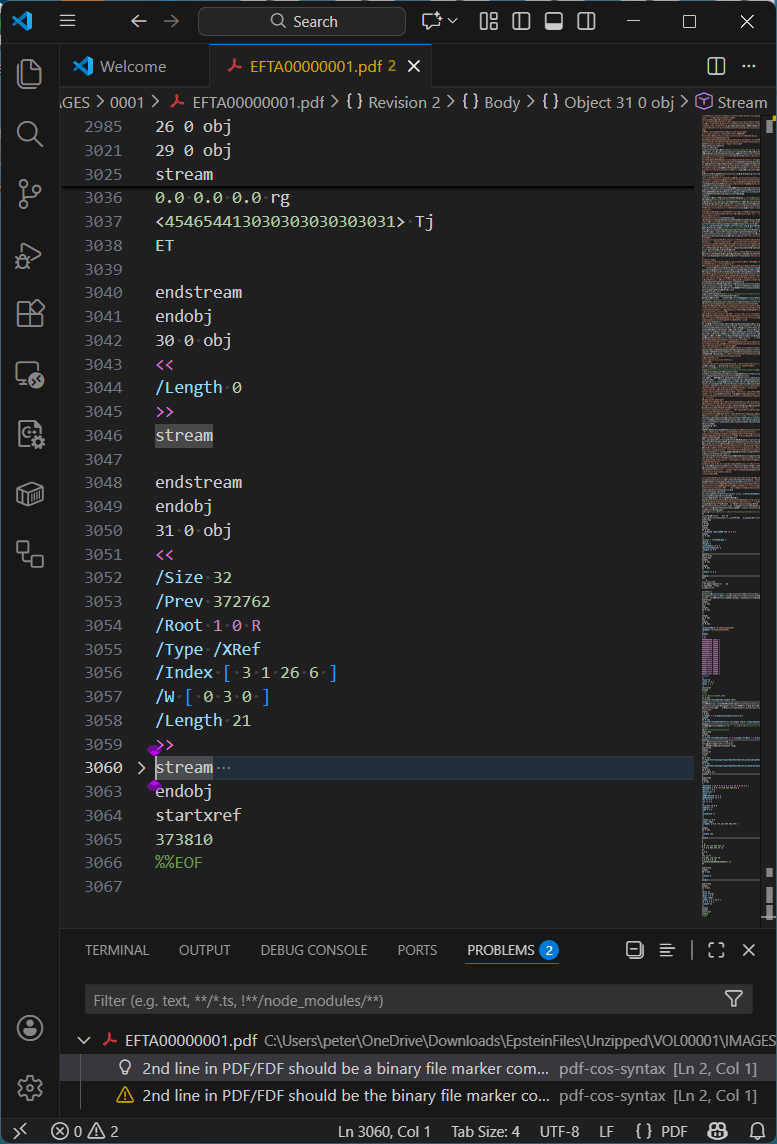
Bates numbering
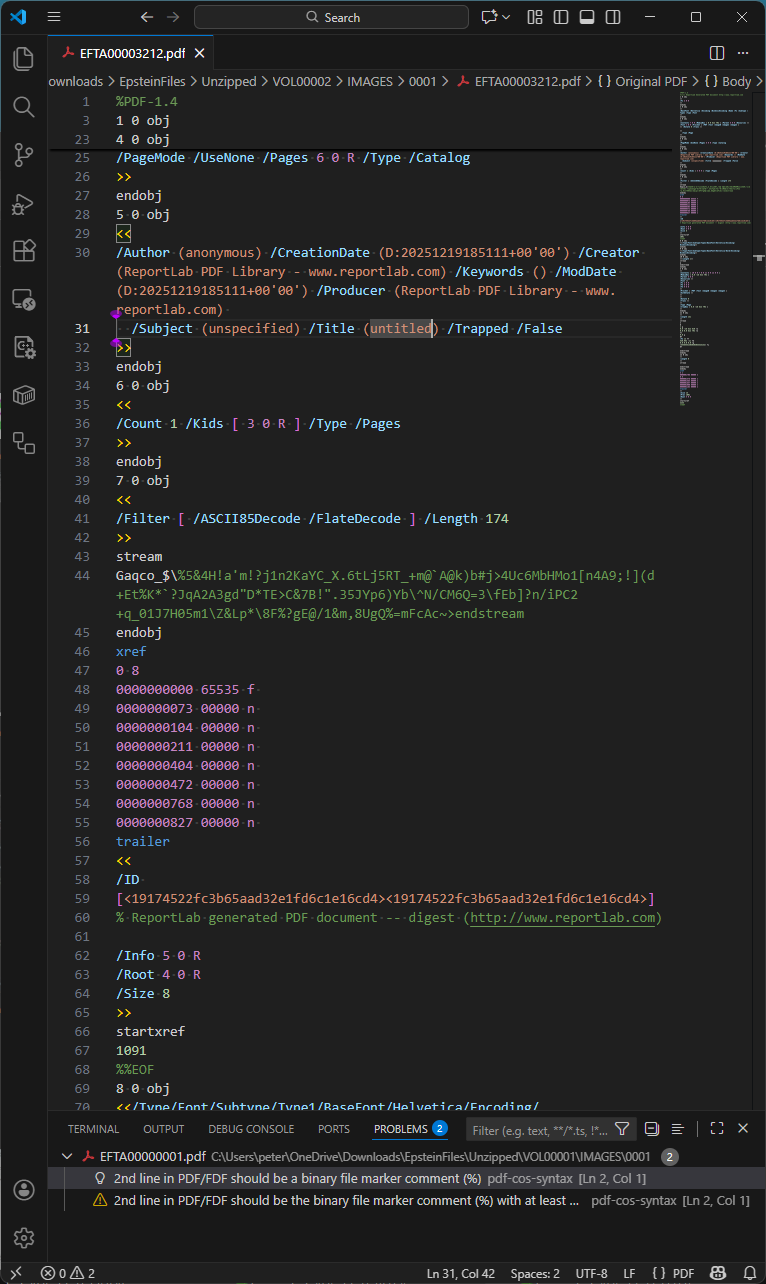
As referenced above, Bates numbering is the job by which each and each page is assigned a trip identifier. For this tranche of Epstein PDF files, Bates numbers were added to each and each page via a separate incremental replace, as proven below in Visible Studio Code with my pdf-cos-syntax extension. Screen that DoJ’s PDFs are basically textual remark-based fully fully internally, making forensic prognosis plenty more uncomplicated – and the files plenty better.
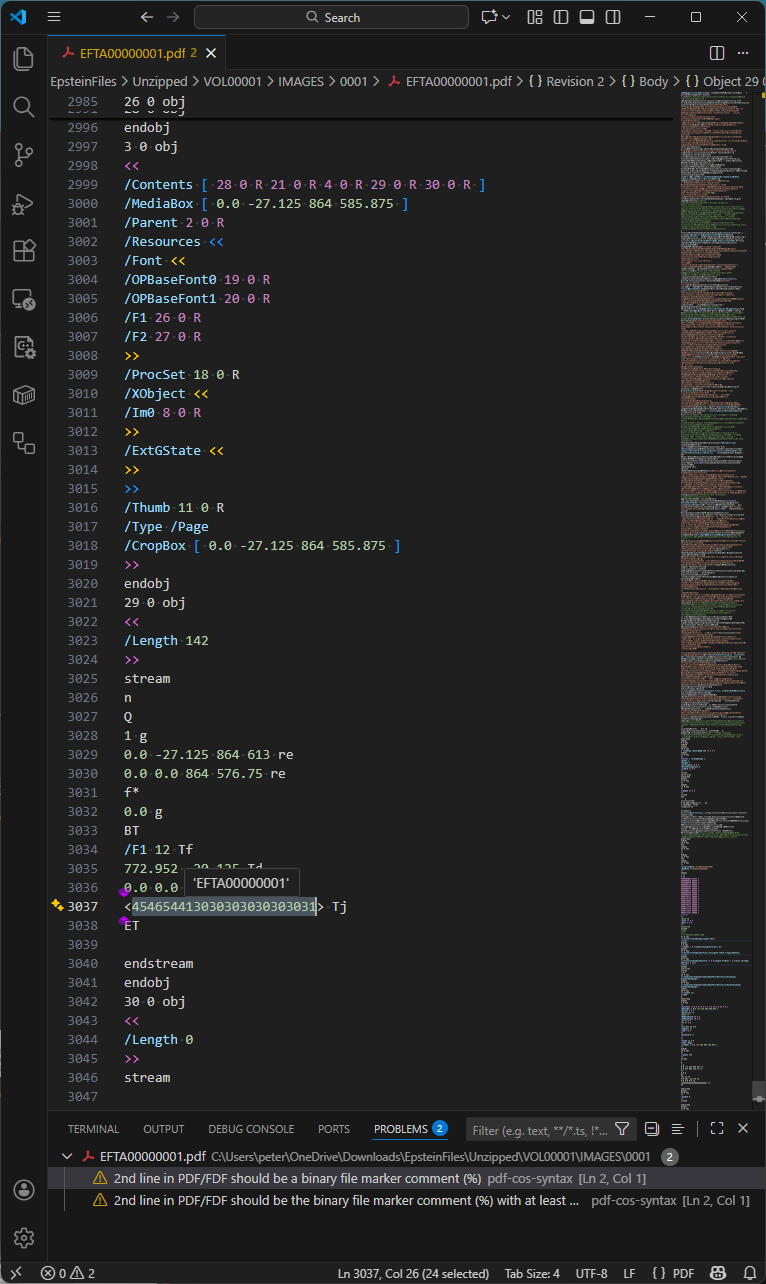
Observations:
- Line 2984 is the terminate-of-file marker for the file version, and line 2985 starts a new incremental replace half.
- Lines 2985-2987 outline object 26, the unembedded Helvetica font helpful resource inclined by the Bates number.
- Lines 2997-3020 are the modified page object (object 3), changing the page object in old revisions of the file.
- Line 2999 is the page Contents array, comprising five separate remark streams, with the 3rd trip (object 29) being the Bates numbering added in this incremental replace. Object 30 is an empty remark trip that can also had been removed by an optimization job.
- Line 3034 models the Helvetica font to 12 point.
- Line 3037 uses a hexadecimal string to paint the Bates number onto the page.
The idiom for this finest incremental replace, which provides the Bates number to each and each page, looks within the entire PDF files we selected at random for investigation. This grunt incremental replace constantly uses a contaminated-reference trip (/Type /XRef) and depends on the old incremental replace, by which the doc catalog Version entry is decided to PDF 1.5.
The first incremental replace
The VSCode pdf-cos-syntax extension also signifies (accurately!) that the brand new PDF is lacking the specified (when the PDF accommodates binary recordsdata, which most originate) comment as the 2d line of the file that signifies to tool that the PDF file has to be treated as binary recordsdata (ISO 32000-2:2020, §7.5.2). Though the lacking comment would not come by the PDF invalid per se, with out this kind of marker shut to the stay of each and each PDF, tool would possibly teach the PDF is a textual remark file, and thus possibly immoral the PDF by altering line endings, which would possibly well fracture the byte offsets within the contaminated-reference recordsdata. On this PDF, the first incremental replace provides this marker comment after a great deal of binary recordsdata, which is pointless.
As mentioned above, the first incremental replace changed the doc catalog Version entry to PDF 1.5, as we ogle in this next screenshot:
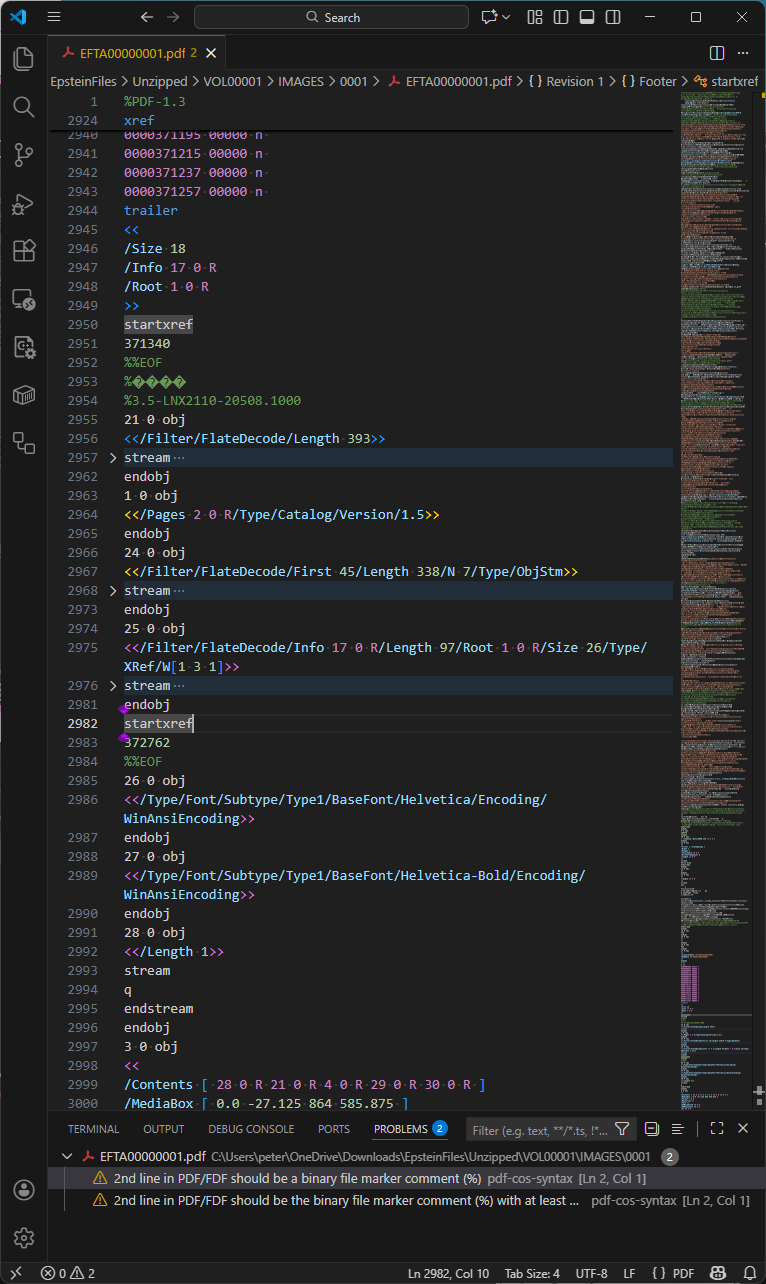
Observations:
- Lines 2953-2984 are the incremental replace half.
- Line 2954 is a PDF comment. PDF comments constantly start up with a PERCENT SIGN (
%) and would possibly well simply occur in many locations in PDF files. Efficient sanitization and redaction workflows in overall rob away all comments from PDFs because they would possibly simply inadvertently repeat recordsdata, but this genuine comment looks in 3,608 diverse PDF files. The foundation or that means of this comment used to be not extra investigated. - Line 2964 upgrades the PDF version to 1.5. Before every little thing look, this is able to possibly also simply seem like completely legitimate PDF, but it completely is technically unsuitable because the file header is
%PDF-1.3yet the Version key used to be handiest added in PDF 1.4 – right here’s what the strict file validation instrument mentioned above had seen. As object 24 is a compressed object trip (traces 2966-2973) and object 25 is a compressed contaminated-reference trip (traces 2974-2981), the indicated version can consider to be PDF 1.5. As a life like topic, on the other hand, this stage of technical detail would not affect operation or behavior of PDFs. - Line 2984 is the terminate-of-half “
%%EOF” marker for this incremental replace half.
As this half of the PDF uses compressed object streams, truly expert PDF forensic tools has to be inclined… simple search methodologies, similar to these mentioned above, would possibly simply not title every little thing!
We all know that there are 7 objects (because we discover /N 7) contained within the item trip:
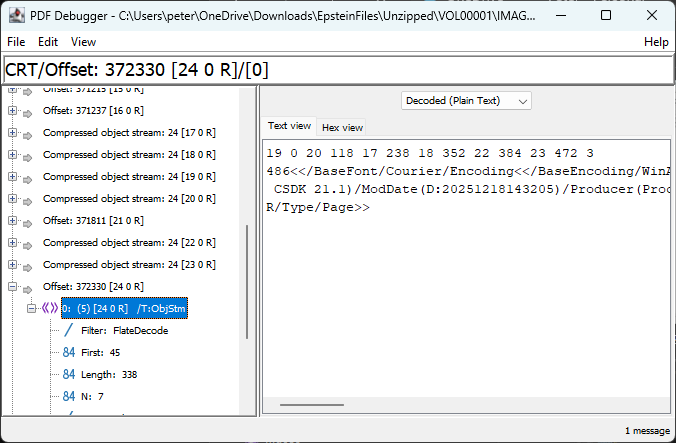
As per PDF’s specification, ISO 32000-2:2020, §7.5.7, the first line of integers is interpreted as N pairs, where the first integer is the item number and the 2d integer is the byte offset relative to the first object within the item trip.
| N | 1st integer (object number) | 2nd integer (start up offset) | Explanation | Advise |
| 1 | 19 | 0 | Type1 Font object for OPBaseFont0 (Courier) | <>/Title/OPBaseFont0/Subtype/Type1/Sort/Font>> |
| 2 | 20 | 118 | Type1 Font object for OPBaseFont1 (Helvetica) | <>/Title/OPBaseFont1/Subtype/Type1/Sort/Font>> |
| 3 | 17 | 238 | Yarn recordsdata (Info) dictionary | <> |
| 4 | 18 | 352 | ProcSet resources array | [/PDF/Text/ImageB/ImageC/ImageI] |
| 5 | 22 | 384 | Assets dictionary for the page | <>/ProcSet 18 0 R/XObject<>>> |
| 6 | 23 | 472 | Array of two indirect references (to remark streams) | [21 0 R 4 0 R] |
| 7 | 3 | 486 | Updated Web page object | <> |
What’s extraordinarily attention-grabbing right here – from a PDF forensics point of view – is the truth of a hidden doc recordsdata dictionary that isn’t referenced from the final (finest) incremental replace trailer (i.e., there’s no Info entry in object 31, traces 3050-3063 below). As such, this orphaned dictionary is invisible to PDF tool! This oddity happens in all diverse PDFs we’d randomly selected for investigation.
Formatted smartly as an uncompressed object, this hidden doc recordsdata dictionary contained within the compressed object trip accommodates the next recordsdata (the CreationDate and ModDate appear to replace in diverse randomly examined PDFs):
17 0 obj
<<
/CreationDate (D:20251218143205)
/ModDate (D:20251218143205)
/Creator (OmniPage CSDK 21.1)
/Producer (Processing-CLI)
>>
endobjThis metadata clearly signifies the tool DoJ inclined to govern these PDF files. Though not relevant to the remark, this forensic discovery clearly reveals that extra care is required when sanitizing PDFs.
Diverse incremental updates
Yet another randomly selected PDF, VOL00003IMAGES�001EFTA00003939.pdf accommodates 3 fat-page photos, and magnificent a single incremental replace that applies the Bates numbering. Nonetheless, in this case the file header is %PDF-1.5 yet each and each the brand new PDF and incremental replace employ aged contaminated-reference tables! This isn’t problematic, but is definitely unexpected and inefficient since PDF 1.5 offered compressed contaminated-reference streams.
By evaluating the objects within the incremental contaminated-reference table to the brand new contaminated-reference table we are able to ogle that objects 66 to 69 – the three Web page objects for the three page doc – were redefined. That is magnificent what’s expected in grunt to add the Bates number to each and each page’s Contents trip as within the old instance.
Our initial examination the utilization of pdfinfo utilities did not title any metadata in any of the PDFs within the tranche, either within the doc recordsdata dictionary (PDF file trailer Info entry) or as an XMP metadata trip (Metadata entry).
Nonetheless, since all of us know that (a) the tranche entails PDFs with incremental updates, and (b) that an orphaned doc recordsdata dictionary exists, all revisions of a doc can consider to be thoroughly examined. Incremental updates would possibly simply consider marked diverse doc recordsdata dictionaries or XMP metadata streams as free but not deleted the grunt recordsdata.
XMP metadata is continually encoded in PDF as a trip object, and since trip objects cannot be in compressed object streams, the utilization of forensic tools to gaze keys “/XML” or “/Metadata” can consider to constantly stumble on them. All novel office suites and PDF advent applications will generate XMP metadata when exporting to PDF. As XMP is frequently uncompressed, looking out for XML fragments can be vital (ogle below for an instance XMP object fragment).
3 0 obj
<>
trip
No longer unsurprisingly for effectively-redacted files, we did not rep any XMP metadata streams or XML in any PDF. As a kill consequence, not one among the PDFs can characterize conformance to either PDF/A (ISO 19005 for long-term archiving) or PDF/UA (ISO 14289 for accessibility). Obviously, as untagged PDFs, the files cannot conform to accessibility specifications similar to PDF/UA or WCAG in any match. Moreover, not one among the PDFs appear to consist of instrument-fair coloration areas.
The presence of an Info entry within the trailer dictionary or (in PDFs with contaminated-reference streams) within the contaminated-reference trip dictionary signifies the presence of doc recordsdata dictionaries. “/Info” does indeed occur in many of the PDFs, including a pair of instances in some PDFs, indicating capacity adjustments via incremental updates. Nonetheless, as stumbled on above, in some cases the finest incremental replace would not consist of an Info entry, thus “orphaning” any gift doc recordsdata dictionaries.
ISO 32000-2:2020, Table 349 lists the outlined entries in PDF’s doc recordsdata dictionary (Title, Writer, Area, and many others). Any vendor would possibly simply add extra entries (similar to Apple does with its /AAPL:Keywords entry), so redaction and sanitization tool can consider to be attentive to extra entries.
From our random sampling, we known one PDF with a non-trivial doc recordsdata dictionary soundless fresh: VOL00002IMAGES�001EFTA00003212.pdf. That is proven below in Visible Studio Code with my pdf-cos-syntax extension:

Of extra passion in this grunt PDF is that the comment at line 60 has survived DoJ’s sanitization and redaction workflow! Other PDF comments would possibly simply therefore even be fresh in diverse files.
EFTA00003212.pdf looks to be a redacted image or an error from the DoJ workflow, as it is a single page with the textual remark “No Images Produced”.
Easy looking out of the standardized PDF doc recordsdata dictionary entries gives the next (point to that the methodology inclined will not stumble on recordsdata in compressed object streams, as mentioned above):
Key title Collection of PDFs (max. = 4,085) Commentary Info 3,823 Some PDFs consider empty Info dictionaries without a entries Title 1 Most efficient EFTA00003212.pdf Writer 1 Most efficient EFTA00003212.pdf Area 1 Most efficient EFTA00003212.pdf Keywords 1 Most efficient EFTA00003212.pdf Creator 1 Most efficient EFTA00003212.pdf Producer 215 Consistently “pypdf” (denotes https://pypi.org/venture/pypdf/) CreationDate 3,609 Identical PDFs which consider ModDate with an the same value ModDate 3,609 Identical PDFs which consider CreationDate with an the same value Trapped 1 Most efficient EFTA00003212.pdf APPL:Keywords 0
Date prognosis
Detailed date prognosis is a current job within the forensic prognosis of possibly false or modified documents. Nonetheless, within the case of redacted or sanitized documents, where the doc is identified to had been modified, this is able to possibly be less vital.
The appearance and modification dates for the three,609 PDFs vary from December 18, 2025, 14:32:05 (2:32 pm) to December 19, 2025, 23:26:13 (nearly center of the night). For all files, the appearance and modification dates are constantly the the same. This would possibly simply additionally imply that the DoJ batch processing to put together this tranche of PDFs took not decrease than 36 hours!
What’s also attention-grabbing is that the CreationDate and ModDate fields within the hidden doc recordsdata dictionary (contained within the item trip of the first increment replace – ogle above) appear to constantly be an genuine match to each and each the CreationDate and ModDate of the brand new doc. This suggests that each and each dates all over all incremental updates were updated in a single processing pass that applied the Bates numbering.
Images
There don't appear to be any JPEG photos (DCTDecode filter) in any PDF within the tranche, including the fat-page photos. Randomly viewing the photographic photos at excessive magnification (zoom) in PDF viewers clearly reveals JPEG “jaggy” compression artifacts. All photographic photos appear to had been downscaled to 96 DPI (769 x 1152 or 1152 x 769 pixels), making textual remark on random objects within the photos noteworthy extra difficult to discern (ogle the OCR dialogue below).
DoJ explicitly avoids JPEG photos within the PDFs possibly because they devour that JPEGs in most cases possess identifiable recordsdata, similar to EXIF, IPTC, or XMP metadata, moreover to COM (comment) tags within the JPEG bitstream. This recordsdata would possibly simply repeat the camera model and serial number, GPS attach, camera operator significant aspects, date/time of the photo, and many others., and is extra complex to redact whereas keeping the JPEG recordsdata. The DoJ processing pipeline has therefore explicitly transformed all lossy JPEG photos to low DPI, FLATE-encoded bitmaps within the PDFs the utilization of an listed instrument-dependent coloration living with a palette of 256 uncommon colours (which reduces the coloration fidelity when put next with the brand new excessive-quality digital coloration picture).
Scanned documents – or are they?
Randomly inspecting the tranche discovers many documents that appear to had been created by a scanning job. On nearer inspection, there are documents which consider repeat-myth artifacts from a physical scanning job, similar to visible physical paper edges, punched holes, staple marks, spiral binding, stamps, paper scuff marks, coloration blotches and inconsistencies, handwritten notes or marginalia, varied paper skew, and platen marks from the physical paper scanning processes. Let's speak, VOL00007IMAGES�001EFTA00009440.pdf reveals many of these aspects
There are also diverse documents that appear to simulate a scanned doc but fully lack the “genuine-world noise” expected with physical paper-based fully fully workflows. The noteworthy crisper photos seem nearly splendid with out random artifacts or background noise, and with the grunt connected quantity of image skew all over a pair of pages. Thanks to the borders around each and each page of textual remark, page skew can with out downside be measured, similar to with VOL00007IMAGES�001EFTA00009229.pdf. It is extremely most likely these PDFs were created by rendering fashioned remark (from a digital doc) to a image (e.g., via print to image or attach to image efficiency) after which making employ of image processing similar to skew, downscaling, and coloration reduction.
The utilization of the timeless monospaced (also identified as fixed-width) “Courier” typeface potential that the dedication of characters redacted would possibly simply additionally be with out downside decided by vertical alignment with textual remark traces above and below each and each redaction. In some circumstances, this is able to possibly also simply cut motivate the imaginable dedication of alternate choices that signify the redacted remark, allowing it to be extra with out downside guessed. Though redaction of variable-width typefaces is a long way extra complex, Bland, M., Iyer, A., and Levchenko, K. 2022 paper “Yarn Beyond the Look: Glyph Positions Fracture PDF Textual remark Redaction” showed that right here's soundless imaginable with ample computing vitality and resolution.
Optical Character Recognition (OCR)
OCR is complex image processing that makes an try to title textual remark in bitmap photos. In PDF files, OCR-known textual remark is many times positioned on high of the image the utilization of the invisible textual remark render mode. This permits customers to then extract the textual remark from the image.
Returning to the very first PDF file within the tranche, VOL00001IMAGES�001EFTA00000001.pdf - right here's a fat-page photo of a hand-written brand where section of the hand-written recordsdata is explicitly redacted. The PDF accommodates largely wrong OCR-ed textual remark, indicating that natural language processing (NLP), machine discovering out (ML), or even language conscious dictionary-based fully fully algorithms were not inclined. This suggests that there shall be extra errors within the extracted textual remark than is extreme.
With cloud platforms readily accessible and supporting advanced OCR at cheap, anyone is in a position to re-processing the entire tranche of PDFs and evaluating the OCR results to these supplied by DoJ. Even supposing the page photos are low-decision (96 DPI), rerunning OCR would possibly simply lift to light extra or corrected recordsdata hidden by the brand new OCR that did not acknowledge every little thing accurately.
The “murky field” redactions we investigated were all accurately applied without prolong into the image pixel recordsdata. They're not separate PDF rectangle objects simply floating above comfortable recordsdata that used to be soundless fresh within the image and with out downside discoverable. Yes, generally it is that simple…!
Conclusion
We did not location out to comprehensively analyze each and each corner of each and each PDF file within the Epstein PDFs, but to fresh a classic stroll-via of among the crucial challenges and techniques inclined to habits a PDF forensic review. Our results above were from a tiny random sample of documents - there would possibly simply smartly be outlier PDFs within the suggestions models that we did not reach upon.
The DoJ has clearly created interior processes, programs, and workflows that would possibly sanitize and redact recordsdata prior to publishing as PDF. This entails changing JPEG photos to low-decision pixel-handiest bitmaps, largely pushing aside metadata, and rendering page photos to bitmaps. OCR looks to had been broadly applied, but is of variable quality.
Their PDF skills shall be improved to vastly cut motivate file measurement by pushing aside needless objects (e.g., empty remark streams, ProcSets, empty thumbnail references, and many others.), simplifying and lowering remark streams, making employ of all incremental updates (i.e., pushing aside all incremental replace sections), and constantly the utilization of compressed object streams and compressed contaminated-reference streams. Info leakage can be happening via PDF comments or orphaned objects inside compressed object streams, as I stumbled on above.
PDF forensics is a extremely complex self-discipline, where variations in files and instrument assumptions can with out downside yield untrue results. The PDF Affiliation hosts a PDF Forensic Liaison Working Community to manufacture substitute steering on forensic examination of PDF files and to remark doc examiners and diverse experts about many of these aspects.

